Tutorial: District Trivia Map - Part 1
Web Scraping Street Addresses With R
I have noticed that a number of websites for shops, social services, and other physical locations will often include a list of addresses on a webpage, but will not include a convenient map that allows you to easily pick the location that is closest to you. This becomes particularly frustrating if you have just moved to a new city and you are not familiar with the surrounding geography, so neighborhood names mean nothing to you. I recently encountered one such problem after moving to the Washington, DC area. My grad school friends and I have developed a bit of a tradition competing in bar trivia about once a week, but the largest trivia organization in the area, District Trivia, provides a list of their locations without providing an overall map.
 When you click on each individual location, however, you are greeted with an address and a small mini-map of just that location:
When you click on each individual location, however, you are greeted with an address and a small mini-map of just that location:
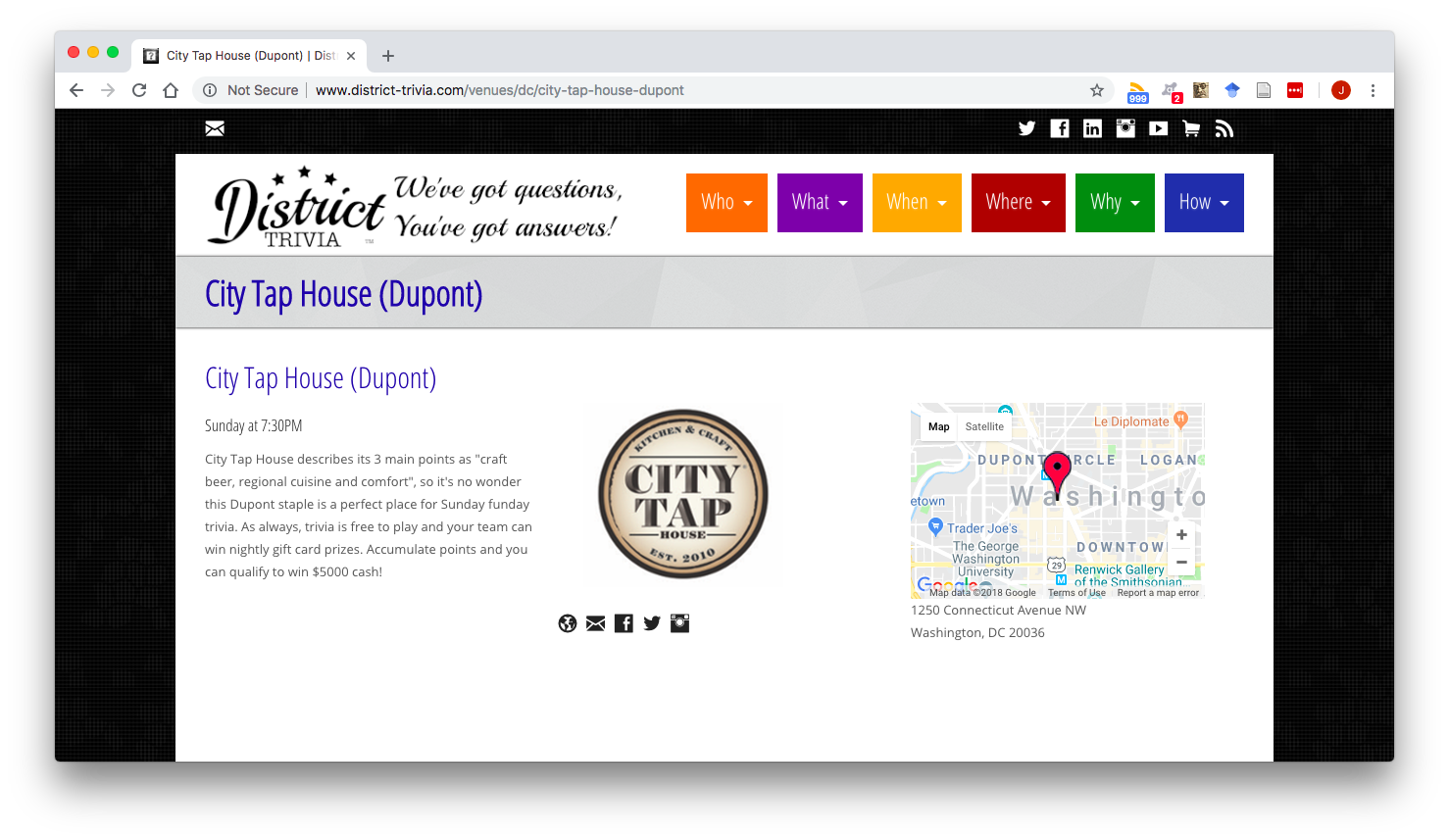 For me, it was a little bit tedious to have to click through every potential location to find one that seemed like it was convenient to my home or office, especially considering that I didn’t know much about the DC Area, and so the “Dupont” description in the title really didn’t mean too much to me. I wanted a single map where I could see all of the locations and could filter them by the day of the week so that it was easier for my friends and I to pick a plausible place to play trivia.
For me, it was a little bit tedious to have to click through every potential location to find one that seemed like it was convenient to my home or office, especially considering that I didn’t know much about the DC Area, and so the “Dupont” description in the title really didn’t mean too much to me. I wanted a single map where I could see all of the locations and could filter them by the day of the week so that it was easier for my friends and I to pick a plausible place to play trivia.
I have already shared the end result of this process on my projects page. As you may be able to guess, the first step to creating this map is to get a full list of the District Trivia locations along with their addresses. If we were to do this manually, it could wind up being quite a chore, considering that there are about 84 different locations listed on the District Trivia website. Luckily, a faster way is made possible through just a few lines of R code:
# install.packages("xml2")
require(xml2)
allLocationsURL <- "http://www.district-trivia.com/where/is-trivia"
doc <- read_html(allLocationsURL)
urls <- xml_find_all(doc,"//div[@class='carousel_item_description']//a[@href]")
locations <- data.frame(name = xml_text(urls),
url=as.character(xml_attrs(urls)),
stringsAsFactors = FALSE)
locations$url <- paste0("http://www.district-trivia.com",locations$url)
output <- data.frame(name=character()
,day=character()
,time=character()
,address=character()
)
for (i in 1:nrow(locations)) {
code <- read_html(locations$url[i])
day.time <- xml_text(xml_find_all(code,'//div[@class="four columns"]//h5'))
day <- gsub(" at.*$","", day.time)
time <- gsub("^.* at ","", day.time)
address.raw <- xml_find_all(code,'//div[@class="four columns"]//p')[2]
address <- xml_text(read_html(gsub("<br>", ", ", address.raw)))
site.data <- data.frame(name=locations$name[i]
,day=day
,time=time
,address=address
,stringsAsFactors = FALSE)
output <- rbind(output,site.data)
}
# write.csv(output, "locations.csv", row.names=FALSE)
This code can be broken down into a handful of sections. We’ll go through them one-by-one to see what each line does.
Loading the necessary packages
# install.packages("xml2")
require(xml2)
Usually, the first thing we do when coding something for R is to install and load packages that will help us accomplish our task. Packages are collections of functions that have been put together as shortcuts, so you don’t have to build everything from scratch.
In this case, we are installing and loading a package called “xml2”, which helps us to look through HTML and XML documents and extract specific content.
The first line begins with a pound symbol to “comment out” this line. If you have already installed the xml2 package, you do not need to do so again. Putting a pound symbol in front of the line tells R to ignore it. If you haven’t installed the package yet, and need to do so, simply delete the pound sign to make the line run.
Read in the HTML code from the page listing all of the Locations
allLocationsURL <- "http://www.district-trivia.com/where/is-trivia"
doc <- read_html(allLocationsURL)
This code first defines a variable called “allLocationsURL” as the address for the page that lists all of the locations where trivia is offered. Then it defines a variable called “doc” which actually records the HTML code from that webpage. After running this code, if we enter “doc” into the console (rather than the script editor), we can see the HTML that was collected. Here’s an excerpt of what should be returned:
> doc
{xml_document}
<html class="" lang="en" dir="ltr">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; char ...
[2] <body class="html not-front not-logged-in no-sidebars page-where ...
Generate a data frame of all locations and the URLs of their individual pages
urls <- xml_find_all(doc,"//div[@class='carousel_item_description']//a[@href]")
locations <- data.frame(name = xml_text(urls),
url=as.character(xml_attrs(urls)),
stringsAsFactors = FALSE)
locations$url <- paste0("http://www.district-trivia.com",locations$url)
Now we want to collect a list of links to each of the locations’ individual pages. We first define a variable called “urls” that collects a list of all of the <a href…> tags in the list on District Trivia’s webpage.
urls <- xml_find_all(doc,"//div[@class='carousel_item_description']//a[@href]")
In this command, xml_find_all is the function that searches an HTML/XML document for specific tags and returns a list of tags that match the parameters you set. Within this function call, “doc” refers to the variable we defined earlier that contains the HTML code. The rest of it, “//div[@class=’carousel_item_description’]//a[@href]”, is in XPath syntax and defines what sort of things we’re looking for. In this case, we are looking for <a href…> tags within <div> tags of class ‘carousel_item_description.’
We know that we’re looking for items with this description based on our inspection of the District Trivia website. Most modern browsers allow you to “inspect element” on webpages by right-clicking on a webpage feature.

When you select “inspect,” a new frame will be introduced to the web page window. As you move your cursor along the HTML code that appears, different aspects of the web page will be highlighted. You can use this to identify the aspects that contain the information you want.

Based on this highlighting, we see that the page elements that contain both the name and link for each location are defined by <div> tags of class ‘carousel_item_description’.
<div class="carousel_item_description">
<h3><a href="/venues/virginia/south-riding-inn">South Riding Inn</a></h3>
</div>
Once you’ve collected all of the webpage elements that fit this description, you can type the name of the variable in which they are held into the console to see what the information looks like.
> head(urls)
{xml_nodeset (6)}
[1] <a href="/venues/dc/lous-city-bar-0">Lou's City Bar</a>
[2] <a href="/venues/dc/public-bar-dupont">Public Bar</a>
[3] <a href="/venues/virginia/falls-church-distillers">Falls Church ...
[4] <a href="/venues/virginia/ragtime">Ragtime</a>
[5] <a href="/venues/virginia/heavy-seas-alehouse-arl">Heavy Seas Al ...
[6] <a href="/venues/virginia/atr-reston">ATR (Reston)</a>
The next bit of code creates a data frame called “locations” that contains two variables: “name” and “url”.
locations <- data.frame(name = xml_text(urls),
url=as.character(xml_attrs(urls)),
stringsAsFactors = FALSE)
The “xml_text” function takes each of the items in the “urls” variables and extracts the text in between the <a…> and </a> tags.
> head(xml_text(urls))
[1] "Lou's City Bar"
[2] "Public Bar"
[3] "Falls Church Distillers"
[4] "Ragtime"
[5] "Heavy Seas Alehouse (ARL)"
[6] "ATR (Reston)"
The “xml_attrs” finds the value of each attribute within the <a…> tag. In this case, the only attribute within that tag is “href.”
> head(xml_attrs(urls))
[[1]]
href
"/venues/dc/lous-city-bar-0"
[[2]]
href
"/venues/dc/public-bar-dupont"
[[3]]
href
"/venues/virginia/falls-church-distillers"
[[4]]
href
"/venues/virginia/ragtime"
[[5]]
href
"/venues/virginia/heavy-seas-alehouse-arl"
[[6]]
href
"/venues/virginia/atr-reston"
This returns a list, rather than a vector which are two different kinds of data storage types in R. To turn it into a character (text) vector, we can contain the command inside the “as.character(…)” function.
> head(as.character(xml_attrs(urls)))
[1] "/venues/dc/lous-city-bar-0"
[2] "/venues/dc/public-bar-dupont"
[3] "/venues/virginia/falls-church-distillers"
[4] "/venues/virginia/ragtime"
[5] "/venues/virginia/heavy-seas-alehouse-arl"
[6] "/venues/virginia/atr-reston"
The only problem now is that these are internal links–they don’t contain the site url. We’ll have to add that before we can move on to the next step. This is what “paste0(…)” does. It combines items within the function into a single string. The final line of this section replaces the “url” variable in the “locations” dataframe with the combination of the current variable and the url for the website.
locations$url <- paste0("http://www.district-trivia.com",locations$url)
Which results in:
> head(locations$url)
[1] "http://www.district-trivia.com/venues/dc/lous-city-bar-0"
[2] "http://www.district-trivia.com/venues/dc/public-bar-dupont"
[3] "http://www.district-trivia.com/venues/virginia/falls-church-distillers"
[4] "http://www.district-trivia.com/venues/virginia/ragtime"
[5] "http://www.district-trivia.com/venues/virginia/heavy-seas-alehouse-arl"
[6] "http://www.district-trivia.com/venues/virginia/atr-reston"
Search the text on each page to find the address
output <- data.frame(name=character()
,day=character()
,time=character()
,address=character()
)
for (i in 1:nrow(locations)) {
code <- read_html(locations$url[i])
day.time <- xml_text(xml_find_all(code,'//div[@class="four columns"]//h5'))
day <- gsub(" at.*$","", day.time)
time <- gsub("^.* at ","", day.time)
address.raw <- xml_find_all(code,'//div[@class="four columns"]//p')[2]
address <- xml_text(read_html(gsub("<br>", ", ", address.raw)))
site.data <- data.frame(name=locations$name[i]
,day=day
,time=time
,address=address
,stringsAsFactors = FALSE)
output <- rbind(output,site.data)
}
This next section first creates an empty data frame called “output” that contains variables for site name, day and time of event, and the address of the event site:
output <- data.frame(name=character()
,day=character()
,time=character()
,address=character()
)
Then it processes the list of URLs we created one by one.
for (i in 1:nrow(locations)) {
code <- read_html(locations$url[i])
day.time <- xml_text(xml_find_all(code,'//div[@class="four columns"]//h5'))
day <- gsub(" at.*$","", day.time)
time <- gsub("^.* at ","", day.time)
address.raw <- xml_find_all(code,'//div[@class="four columns"]//p')[2]
address <- xml_text(read_html(gsub("<br>", ", ", address.raw)))
site.data <- data.frame(name=locations$name[i]
,day=day
,time=time
,address=address
,stringsAsFactors = FALSE)
output <- rbind(output,site.data)
}
This for loop knows how many times to repeat the actions within the {…} by counting the number of rows in the locations data frame we created. Then, one-by-one, it looks at each URL that we found in the last step and reads in the HTML code. It uses “xml_text(…)” to find the HTML tag containing the date and time of the event at that url in a similar process as before.
As you can see from the screenshot below, both day and time are contained within the same set of <div> tags.
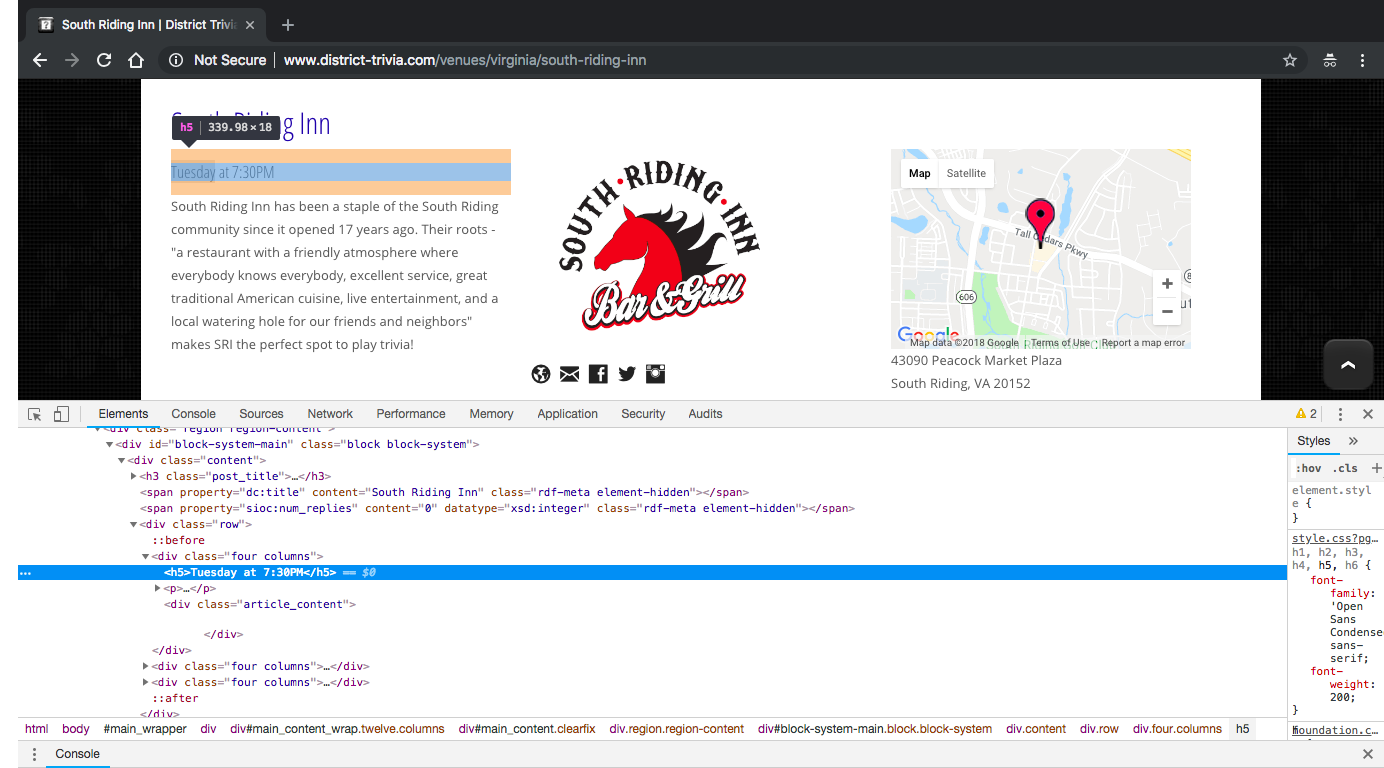
<div class="four columns">
<h5>Tuesday at 7:30PM</h5>
<p>South Riding Inn has been a staple of the South Riding community since it opened 17 years ago. Their roots - "a restaurant with a friendly atmosphere where everybody knows everybody, excellent service, great traditional American cuisine, live entertainment, and a local watering hole for our friends and neighbors" makes SRI the perfect spot to play trivia! </p>
<div class="article_content">
</div>
</div>
In the end, we want the time and date to be in two separate variables, so we need to add a bit of R code to separate them. This is done in the following lines.
day <- gsub(" at.*$","", day.time)
time <- gsub("^.* at ","", day.time)
Both of these lines use regex to find the word “at” and delete either (1) it and all the text after it or (2) it and all of the text before it. This essentially selects (1) only the text before “at” or (2) only the text after “at.”
The next two lines essentially replicate the same process as we’ve used before with XML. The only difference is the “[2]” after the xml_find_all(…) function.
address.raw <- xml_find_all(code,'//div[@class="four columns"]//p')[2]
address <- xml_text(read_html(gsub("<br>", ", ", address.raw)))
This “[2]” is necessary because there are actually two <p> tags within <div> tags of class “four columns” within each event page. The second of these is what contains the address. We also use gsub(…) to replace the break row tag–which creates a new line–with a comma to help preserve the address format when we run xml_text(…)
The final set of lines create a data frame of the variables that we just created and then appends it to the output data frame that we created before starting the for loop.
site.data <- data.frame(name=locations$name[i]
,day=day
,time=time
,address=address
,stringsAsFactors = FALSE)
output <- rbind(output,site.data)
This creates a record of all of the events that we can then export as an excel or csv document.
Save the output of this process as a CSV filter
# write.csv(output, "locations.csv", row.names=FALSE)
This last line saves the output data frame we created as a CSV file in your working directory. (If you don’t know what your working directory is, you can type “getwd()” into the console.) If you add the row.names=FALSE option, your CSV will start with a variable that represents the row number in the output data frame. I find this annoying, so I prevent R from producing it. I also usually leave this line commented out until I am sure that the entire process worked correctly, then I will delete the # and run the line to save my results.
Now that we have the addresses, we’re ready to geocode them. I will cover this process in next week’s blog post.
comments powered by Disqus